Mcmc-сэмплинг для тех, кто учился, но ничего не понял
Содержание:
- Примеры применения
- Пример (задача о моллюсках)
- Мотивация
- Examples of Sampling Errors
- Мнения
- Downsampling
- Sampling Basics¶
- Удаление примеров мажоритарного класса
- Population Distribution Marriages
- Виды сэмплинга
- Как организовать сэмплинг
- Презентация на тему: » Виды и формы СЭМПЛИНГА.. Цели СЭМПЛИНГА: Завоевать новых покупателей. Удержать существующих потребителей. Увеличить потребление продукта, как постоянными.» — Транскрипт:
- Sampling Error vs. Non-sampling Error
- Итоги
Примеры применения
На практике в бизнес-аналитике применяется подход, когда для анализа из исходного набора данных формируется новое. Это обусловлено различными обстоятельствами, в том числе:
Снижение трудоемкости алгоритмов Data Mining. При анализе сравнительно небольшого подмножества данных временные и вычислительных затраты значительно сокращаются.
Коррекция распределений значений переменных в выборке. В некоторых случаях исходное распределение значений факторов в имеющимся наборе данных может негативно сказываться на процессе обучения модели. Типичный пример – несбалансированность классов в задаче кредитного скоринга. Коррекция распределений может заключаться, например, в увеличении числа объектов с требуемыми характеристиками (oversampling), в сокращении избыточных примеров (undersampling).
Пример (задача о моллюсках)
Сравним практически некоторые из описанных стратегий на наборе данных про моллюсков (набор данных взят с UCI machine learning repository). В нем представлены физиологические сведения об этих животных. Имеются следующие поля:
- пол;
- длина;
- диаметр (линия, перпендикулярная длине);
- высота;
- масса всего моллюска;
- масса без раковины;
- масса всех внутренних органов (после обескровливания);
- масса раковины (после высушивания);
- зависимая переменная: количество колец (в год на раковине моллюска появляется 1,5 кольца).
Изначально набор данных предназначен для решения задачи регрессии. По количеству колец на раковине определяется возраст моллюска. Для классификации в условиях несбалансированности создадим новую выходную переменную, принимающую только два значения. Для этого, предположим, что если количество колец у моллюска не превосходит 18, то для нас он будет считаться молодым, в противном случае – старым.
Также проимитируем ситуацию различия издержек и рассмотрим случаи, когда неверное отнесение старого моллюска к молодым может принести бо́льшие издержки, чем в случае неверной классификации фактически молодого.
Таким образом, мы получили набор данных с сильно несбалансированными классами, где значение «молодой» было присвоено 4083 записям (97,7%), а значение «старый» – 94 записям (2,3%). Далее стратифицированным сэмплингом были получены тестовый и обучающий наборы данных.
Прежде чем восстанавливать баланс между классами, вернемся к понятию издержек классификации. Во многих приложениях, таких как кредитный скоринг, директ-маркетинг, издержки при ложноположительной ($С_{10}$) классификации в несколько раз выше, чем при ложноотрицательной (обозначим их как $С_{01}$). При пороге отсечения 0,5 количество миноритарных примеров необходимо увеличить в $С_{10}/С_{01}$ раз (при условии что $С_{00} = С_{11} = 0$). Либо во столько же уменьшить мажоритарный класс (теоретическое обоснование этого утверждения изложено в работе ).
Сравним следующие подходы к восстановлению баланса между классами: случайное удаление примеров мажоритарного класса, дублирование примеров миноритарного класса, специальные методы увеличения числа примеров (алгоритмы SMOTE и ASMO).
Для алгоритмов SMOTE и ASMO количество ближайших соседей для генерации примеров установим равным 5.
Алгоритм ASMO признал набор данных нерассеянным (среди 100 ближайших соседей не нашлось даже 20 примеров из мажоритарного класса). Однако проигнорируем это сообщение и посмотрим, какой будет результат, если генерировать примеры, используя записи из каждого класса. Для кластеризации применен алгоритм k-means (k = 5).
После восстановления баланса строилась логистическая регрессия с порогом отсечения 0,5, и подсчитывались издержки. Результаты представлены на рисунке 7.
Из рисунка 6 видно, что наилучшим образом показал себя алгоритм SMOTE, так как издержки в данном случае оказались самыми меньшими. ASMO проявил себя хуже, однако стоит напомнить, что набор данных не рассеян и согласно данной стратегии необходимо было использовать SMOTE.
Итак, мы рассмотрели различные подходы сэмплинга для решения проблемы несбалансированности классов. Помимо него существуют стратегии, согласно которым происходит модификация алгоритма обучения, но их рассмотрение выходит за рамки данной статьи.
В таблице 1 приведено описание файлов с наборами данных, которые использовались в примере. Их можно найти в архиве.
Таблица 1 – Наборы данных
| Описание набора данных | Файл |
|---|---|
| Исходный набор данных: Abalone Data Set (классы не выделены) | abalone_data.txt |
| Исходный обучающий набор данных | dataset75.txt |
| Тестовый набор данных | testdataset.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:3 | syntsmote1_3.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:5 | syntsmote1_5.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:10 | syntsmote1_10.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:15 | syntsmote1_15.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:3 | syntasmot1_3.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:5 | syntasmot1_5.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:10 | syntasmot1_10.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:15 | syntasmot1_15.txt |
Мотивация
Сглаживание проявляется в случае 2D-изображений в виде муара и пиксельных краев, в просторечии известных как « неровности ». Общие обработки сигналов и обработка изображений знания предполагают , что для достижения идеального устранения наложения спектров , надлежащие пространственный отбора проб на Найквист скорости (или выше) после применения 2D сглаживающего фильтра не требуются. Поскольку этот подход потребовал бы прямого и обратного преобразования Фурье , были разработаны менее требовательные в вычислительном отношении приближения, такие как суперсэмплинг, чтобы избежать переключений областей, оставаясь в пространственной области («области изображения»).
Examples of Sampling Errors
Assume that XYZ Company provides a subscription-based service that allows consumers to pay a monthly fee to stream videos and other types of programming via an Internet connection.
The firm wants to survey homeowners who watch at least 10 hours of programming via the Internet per week and that pay for an existing video streaming service. XYZ wants to determine what percentage of the population is interested in a lower-priced subscription service. If XYZ does not think carefully about the sampling process, several types of sampling errors may occur.
A population specification error would occur if XYZ Company does not understand the specific types of consumers who should be included in the sample. For example, if XYZ creates a population of people between the ages of 15 and 25 years old, many of those consumers do not make the purchasing decision about a video streaming service because they may not work full-time. On the other hand, if XYZ put together a sample of working adults who make purchase decisions, the consumers in this group may not watch 10 hours of video programming each week.
Selection error also causes distortions in the results of a sample. A common example is a survey that only relies on a small portion of people who immediately respond. If XYZ makes an effort to follow up with consumers who don’t initially respond, the results of the survey may change. Furthermore, if XYZ excludes consumers who don’t respond right away, the sample results may not reflect the preferences of the entire population.
Мнения
Заместитель генерального директора ОАО «КапиталЪ Страхование» Дмитрий Боткин:
Сэмплинг страховых услуг может эффективно работать на больших массивах страхователей. Предложение бесплатных, «на пробу» страховых услуг в торговых центрах не окупает вложенных затрат: не та целевая аудитория. Сегодня страховщики собрали большие базы данных только по ОСАГО, и это опять-таки не та целевая аудитория. По этим базам число обратившихся в страховую компанию по рассылке методом директ-маркетинга не превысит 1%, а купят страховой полис еще меньше. Сэмплинг может хорошо работать только на массивах потенциальных страхователей с откликом не ниже 10%, а это уже хорошо подготовленная к финансовым услугам аудитория, которая пока есть только у банков. Вопрос только в том, готовы ли банки поделиться своими клиентами со страховщиками.
Директор по маркетингу группы «Альфа-Страхование» Евгений Белобородов:
Одна из основных причин, по которым сэмплинг не может быть в полной мере применен к страхованию, сводится к стоимости страхового продукта и циклу его потребления. Цикл потребления пищевых продуктов обычно составляет несколько дней. Распробовав йогурт или сок, человек очень быстро начинает совершать покупки за свой счет. В страховании же стандартный цикл потребления равен одному году. Стоимость упаковки йогурта, стакана сока, даже недельного пропуска в тренажерный зал или открытого тест-драйва просто несравнима с возможными затратами страховщика на восстановление автомобиля клиента после серьезной аварии и оплату лечения водителя при полученных травмах. Разбрасываться такими дорогими подарками страховым компаниям невыгодно.
Недельный же полис страхования не дает клиенту представления о страховом продукте — для этого надо, как минимум, успеть получить страховое возмещение, а вероятность наступления страхового события в недельный срок крайне мала: почувствовать «вкус» продукта практически невозможно.
Генеральный директор «Русской страховой компании» Геннадий Смирнов:
Недостаточное развитие сэмплинга в страховании, то есть бесплатных полисов, может быть связано с особенностями ведения бухгалтерского учета и налогообложения страховых компаний. Страховщику в случае выдачи бесплатного страхового полиса придется формировать страховые резервы за свой счет, из прибыли, что сильно повышает цену сэмплинг-акции. Правда, есть еще один способ, но он не приветствуется. Это оформить бесплатные полисы как платные за счет «серых» средств.
Генеральный директор СК «МРСС» Семен Акерман:
Подарки, которые дарит страховая компания, должны быть со смыслом и отражать сущность страхования. Тогда такая акция будет максимально стремиться к сэмплингу. Очень удачный пример встретился мне в Германии. Одна из страховых компаний делала подарок в виде молотка для разбивки лобового стекла при ДТП. Слоган у этой компании звучал примерно так: «В трудной ситуации мы думаем о вас». Понятно, что и молоток, и страхование имели своей целью «протянуть страхователю руку помощи в трудной ситуации».
Но в этом деле главное — не перегнуть палку. А то будем дарить бейсбольные биты с надписью «Всем врагам BMW посвящается».
Д.Брызгалов
Независимый эксперт
Downsampling
Итак, при уменьшении частоты дискретизации упрощённо происходит два этапа:
- Цифровая фильтрация сигнала для того, чтобы удалить высокочастотные составляющие, которые не удовлетворяют пределу Найквиста для новой частоты дискретизации;
- Удаление или (отбрасывание) лишних отсчетов (сохраняется каждый N-й отсчёт). Здесь следует пояснить, что при программной реализации алгоритма децимации «лишние» отсчёты не удаляются, а просто не вычисляются (отбрасываются). При этом число обращений к цифровому фильтру уменьшается в определённое количество раз.
Так вот. Второй этап удаление или (отбрасывание) лишних отсчетов в англоязычной литературе иногда обозначают термином downsampling, что по сути может употребляться как синоним термина «децимация».
Sampling Basics¶
Before jumping into IQ sampling, let’s discuss what sampling actually means. You may have encountered sampling without realizing it by recording audio with a microphone. The microphone is a transducer that converts sound waves into an electric signal (a voltage level). That electric signal is transformed by an analog-to-digital converter, producing a digital representation of the sound wave. To simplify, the microphone captures sound waves that are converted into electricity, and that electricity in turn is converted into numbers. SDRs are surprisingly similar. Instead of a microphone, however, they utilize an antenna. In both cases, the voltage level is sampled with an analog-to-digital converter. For SDRs, think radio waves in then numbers out.
Whether we are dealing with audio or radio frequencies, we must sample if we want to capture, process, or save a signal digitally. Sampling might seem straightforward, but there is a lot to it. A more technical way to think of sampling a signal is grabbing values at moments in time and saving them digitally. Let’s say we have some random function, , which could represent anything, and it’s a continuous function that we want to sample:
We record the value of at regular intervals of seconds, known as the sample period. The frequency at which we sample, i.e., the number of samples taken per second, is simply . We call this the sample rate, and its the inverse of the sample period. For example, if we have a sample rate of 10 Hz, then the sample period is 0.1 seconds; there will be 0.1 seconds between each sample. In practice our sample rates will be on the order of hundreds of kHz to tens of MHz or even higher. When we sample signals, we need to be mindful of the sample rate, it’s a very important parameter.
Удаление примеров мажоритарного класса
Рассмотрим классические стратегии удаления примеров мажоритарного класса из набора данных.
Случайное удаление примеров мажоритарного класса (Random Undersampling)
Это самая простая стратегия. Для этого рассчитывается число $K$ – количество мажоритарных примеров, которое необходимо удалить для достижения требуемого уровня соотношения различных классов (один из способов того, как это сделать, будет описан в экспериментальной части). Затем случайным образом выбираются $K$ мажоритарных примеров и удаляются.
На рисунке 1 изображены примеры некоторого набора данных в двумерном пространстве признаков до и после использования указанной стратегии сэмплинга.
Примеры из мажоритарного класса могут удаляться не только случайным образом, но и по определенным правилам. Перейдем к рассмотрению таких стратегий.
Поиск связей Томека (Tomek Links)
Пусть примеры $E_i$ и $E_j$ принадлежат к различным классам, $d(E_i, E_j)$ – расстояние между указанными примерами. Пара $(E_i, E_j)$ называется связью Томека, если не найдется ни одного примера $E_l$ такого, что будет справедлива совокупность неравенств (1):
$\begin{cases}
{d(E_i, E_l)
Согласно данному подходу, все мажоритарные записи, входящие в связи Томека, должны быть удалены из набора данных. Этот способ хорошо удаляет записи, которые можно рассматривать в качестве «зашумляющих». На рисунке 2 визуально показан набор данных в двумерном пространстве признаков до и после применения стратегии поиска связей Томека.
Правило сосредоточенного ближайшего соседа (Condensed Nearest Neighbor Rule)
Пусть L – исходный набор данных. Из него выбираются все миноритарные примеры и (случайным образом) один мажоритарный. Обозначим это множество как S. Все примеры из L классифицируются по правилу одного ближайшего соседа (1-NN). Записи, получившие ошибочную метку, добавляются во множество S (рисунок 3).
Таким образом, мы будем учить классификатор находить отличие между похожими примерами, но принадлежащими к разным классам.
Односторонний сэмплинг (One-side sampling, one-sided selection)
Главная идея этой стратегии – это последовательное сочетание предыдущих двух, рассмотренных выше.
Для этого на первом шаге применяется правило сосредоточенного ближайшего соседа, а на втором – удаляются все мажоритарные примеры, участвующие в связях Томека.
Таким образом, удаляются большие «сгустки» мажоритарных примеров, а затем область пространства со скоплением миноритарных очищается от потенциальных шумовых эффектов.
Правило «очищающего» соседа (neighborhood cleaning rule)
Эта стратегия также направлена на то, чтобы удалить те примеры, которые негативно влияют на исход классификации миноритарных.
Для этого все примеры классифицируются по правилу трех ближайших соседей. Удаляются следующие мажоритарные примеры:
- получившие верную метку класса;
- являющиеся соседями миноритарных примеров, которые были неверно классифицированы.
Теперь рассмотрим другой подход – увеличение числа примеров миноритарного класса.
Population Distribution Marriages
Many inhabitants never married (yet), in which case marriages is zero. Other inhabitants married, divorced and remarried, sometimes multiple times. The histogram below shows the distribution of marriages over our 976 inhabitants.
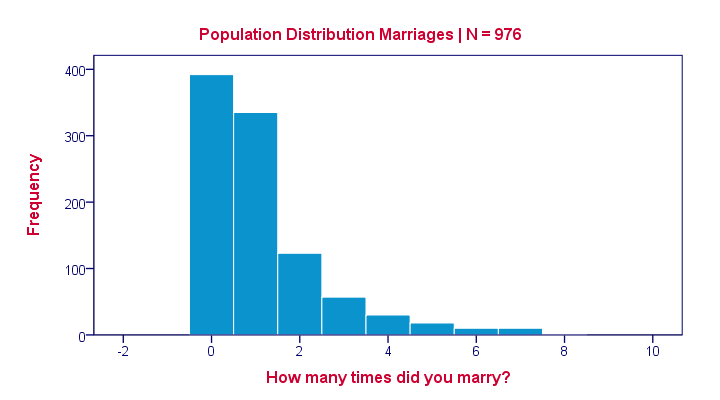
Note that the population distribution is strongly skewed (asymmetrical) which makes sense for these data. On average, people married some 1.1 times as shown by some descriptive statistics below.

These descriptives reemphasize the high skewness of the population distribution; the skewness is around 1.8 whereas a symmetrical distribution has zero skewness.
Виды сэмплинга
Сэмплинг — отличный способ стимулирования продаж в ритейле. Его организация в точках продаж позволяет подключать эмоции потенциальных покупателей и мотивирует их делать спонтанные покупки. Однако, сэмплинг не обязательно проводят на территории магазина или торгового центра. Некоторые компании предлагают образцы своей продукции прямо на улице. Ознакомьтесь подробнее с видами сэмплинга.
- Обмен (Switch-sampling). Подразумевает обмен наполовину пустой упаковки используемого товара на новый. Такой подход помогает клиенту сравнить качество аналогичных товаров.
- Сухой сэмплинг (dry sampling). Предполагает рекламу продукта в точке продажи. Потенциальным покупателям предлагают взять с собой пробник бальзама для волос, крема, зубной пасты или другого товара.
- Влажный сэмплинг (wet sampling). Предоставляет целевой аудитории возможность продегустировать товар на месте. Например, колбасные изделия, сыр, масло, йогурт и так далее.
- HoReCa сэмплинг (Hotel-Restaurant-Cafe sampling). Это дегустация алкогольных и безалкогольных напитков, а также сигарет. Такой сэмплинг чаще всего организовывают в ресторанах, кафе, гостиницах и преподносят как комплимент от заведения или подарок при заказе на определенную сумму.
- Домашний сэмплинг (house-to-house sampling). Предполагает рассылку примеров товара почтой. Это может быть мини-версия продукта или печатная реклама с образцами и многое другое.
Теперь, когда вы знаете виды сэмплинга, самое время узнать, как правильно его организовать.
Как организовать сэмплинг
- Установите цели и задачи сэмплинга
- Подберите продукт и установите объем сэмпла
- Выберите время проведения сэмплинга
- Выберите место проведения сэмплинга
- Соберите команду промоутеров
Чтобы организовать эффективный сэмплинг, воспользуйтесь следующими полезными рекомендациями.
Установите цели и задачи сэмплинга. Прежде чем приступать к организационным вопросам, подумайте, зачем вам нужна эта акция, чего вы хотите достичь с ее помощью. Подготовьте маркетинговый план и по пунктам пропишите пути достижения каждой задачи.
Подберите продукт и установите объем сэмпла
В этом вопросе важно полагаться на интересы и предпочтения целевой аудитории. Тщательно продумайте, что вы будете предлагать, как и в каком количестве
Пропишите расходы, необходимые для организации сэмплинга.
Выберите время проведения сэмплинга. Установите, когда лучше всего взаимодействовать с целевой аудиторией. Сэмплинг может проводится на протяжении всего дня или в какие-то определенные часы. Такой подход позволит сконцентрировать усилия на потенциальных покупателях и не распылять свои ресурсы.
Выберите место проведения сэмплинга. На основании данных о своей целевой аудитории выявите наиболее релевантные точки проведения акции. Подумайте, где больше всего ваших потенциальных покупателей. При этом помните, что клиент должен иметь возможность купить товар, иначе он может передумать и все усилия будут сведены к минимуму.
Соберите команду промоутеров. В этом вопросе важно учесть пол, возраст и другие характеристики, которые могут влиять на уровень доверия вашей целевой аудитории.
При правильном подходе сэмплинг способен увеличить объем продаж на 200-300%. Однако, эффективность не всегда можно измерить в денежном эквиваленте, ведь ознакомление целевой аудитории с продукцией это еще и работа на перспективу. Используйте инструменты ATL и BTL-рекламы, задействуйте мессенджеры и социальные сети, чтобы увеличить количество точек контакта с клиентом.
Презентация на тему: » Виды и формы СЭМПЛИНГА.. Цели СЭМПЛИНГА: Завоевать новых покупателей. Удержать существующих потребителей. Увеличить потребление продукта, как постоянными.» — Транскрипт:
1
Виды и формы СЭМПЛИНГА.

2
Цели СЭМПЛИНГА: Завоевать новых покупателей. Удержать существующих потребителей. Увеличить потребление продукта, как постоянными клиентами, так и через привлечение новых. Поощрять покупателей пользоваться продуктами лучшего качества. Вывести, презентовать новый продукт. Улучшить отношения с торговой сетью. Расширить дистрибуцию.

3
Основные формы СЭМПЛИНГА: Сэмплинг – товар упакован, его можно унести с собой домой и употребить по назначению; Дегустация – непосредственное предложение небольшого количества продукта на пробу.

4
Виды СЭМПЛИНГА : Wet ( «мокрый» ) sampling (дегустация) — потребителю предлагают попробовать продукт немедленно, чаще всего — непосредственно в точке продажи. Может быть использован по любым продуктам питания.

5
Применяется очень широко в практике современного бизнеса Психологическое воздействие достаточно велико, при правильно спланированной кампании сказывается увеличением продаж немедленно.

6
Dry ( «сухой» ) sampling – покупателю рассказывают о торговой марке, отличительных особенностях и дают образец продукта, который, при желании, можно попробовать дома. Используется для таких товаров, как сухие завтраки, моющие средства, декоративная косметика

7
Раздача образцов может проходить на улице, на презентации, дискотеках и т.д. Иногда это может осуществляться в виде прямой рассылки – direct mail – в качестве вложений в выписываемые журналы.

8
К нему обычно прибегают компании,пользующиеся силовой стратегией на рынке, т.е. имеющие устойчивое финансовое положение и мощный брэнд и стремящиеся удержать свой внушительный рыночный сегмент с помощью затратных промоушн акций.

9
Horeca ( Hotel – Restaurant – Café ) — семплинг в гостиницах, ресторанах и кафе.

10
Довольно широко распространен в индустриально развитых странах. Заключается обычно в предложении бесплатной дегустации сигарет, кофе, алкогольных и безалкогольных напитков, разовых пробных услуг парикмахеров, массажистов и пр.

11
House – to – house sampling — ( домашний семплинг ) – рассылка образцов продукции для ознакомления с ней потребителей и стимулирование таким образом сбыта.

12
Основные методы здесь – это непосредственная рассылка, подвешивание образцов на дверные ручки, запечатывание их в пакеты с газетами и журналами и в упаковки с товарами, рассылаемыми по почте.

13
Исследования показывают, что у образцов, доставленных на дом, гораздо больше шансов быть испробованными немедленно, чем у тех, что раздаются в местах прогулок.

14
КАК МАРКЕТОЛОГИ ОТСЛЕЖИВАЮТ ДОХОД ОТ ВЛОЖЕНИЙ ???

15
КАКОВА ВЫГОДА КОМПАНИИ, ТОРГУЮЩЕЙ ПО КАТАЛОГУ И ПРЕДОСТАВЛЯЮЩЕЙ КАНАЛ ДЛЯ СЭМПЛИНГА ???

16
Дегустация как разновидность СЭМПЛИНГА : Прямая – опробуется приготовленный продукт и Сухая (без опробования продукта) – подразумевает информирование покупателя о торговой марке, способе ее употребления, отличительных особенностях ( т. е. реализуется только в месте продаж ), Расстановочная.

17
ДЕГУСТАЦИЯ –это метод продвижения продовольственных товаров, в основе которого лежит объективный фактор психологии человека – доверие своим собственным ощущениям.

18
Категории товаров, наилучшим образом подходящие для дегустации, производятся для сегментов рынка с относительно большой емкостью.

19
Эта продукция должна обладать и следующими свойствами: Нацеленность этих товаров на широкого потребителя ; Быть продукцией частых повторных продаж одним и тем же лицам ; Являться продукцией с невысокой себестоимостью.

20
При этом следует дать ответы на традиционные вопросы: Какова цель ? Где и когда проводятся акции ? Что должны дегустировать покупатели ? Как и кто их должен проводить ?

21
Дегустации и распространение образцов гармонично вписываются в коммуникационную стратегию «втягивания » Ее цель: создать на уровне конечного спроса благоприятное отношение к товару, побуждающее посредников к вынужденному сотрудничеству с производителями.

22
Дегустации можно рассматривать еще и как механизм инвестирования в ИМИДЖ предприятия производителя и его торговую марку, преследующий цель – создать ИМИДЖ марки и приобрести КАПИТАЛ ИЗВЕСТНОСТИ.

23
По результатам проведения акций ежемесячно предоставляется отчет, содержащий : Первичная информация для маркетологов; Информация о динамике объемов продаж, перед дегустацией; Динамика объемов продаж во время проведения дегустации; Изменение динамики через 2 недели после акции.

Sampling Error vs. Non-sampling Error
There are different types of errors that can occur when gathering statistical data. Sampling errors are the seemingly random differences between the characteristics of a sample population and those of the general population. Sampling errors arise because sample sizes are inevitably limited. (It is impossible to sample an entire population in a survey or a census.)
A sampling error can result even when no mistakes of any kind are made; sampling errors occur because no sample will ever perfectly match the data in the universe from which the sample is taken.
Company XYZ will also want to avoid non-sampling errors. Non-sampling errors are errors that result during data collection and cause the data to differ from the true values. Non-sampling errors are caused by human error, such as a mistake made in the survey process.
If one group of consumers only watches five hours of video programming a week and is included in the survey, that decision is a non-sampling error. Asking questions that are biased is another type of error.
Итоги
Алгоритмам для решения задачи с бандитом нужно искать компромисс между исследованием и использованием. Им нужно искать лучшие действия, при этом пытаясь воспользоваться уже полученной информацией.
В простом алгоритме, например, эпсилон-жадном (epsilon-greedy), компромисс по большей части достигается с помощью использования действия, которое сейчас даёт максимальное вознаграждение, и добавления простого исследования, а затем случайно выбирается какое-то другое действие. В более сложных решениях вроде UCB часто выбираются действия с максимальным вознаграждением, но это уравновешивается измерением достоверности. Это гарантирует проверку действий, которые редко выбирались.
Сэмплирование Томпсона предлагает иной подход. Вместо простого вычисления ожидания вознаграждения оно постепенно улучшает модель вероятности вознаграждения для каждого действия, а сами действия выбираются на основе образцов из распределения. Поэтому можно получить ожидание среднего значения вознаграждения, а также вычислить достоверность этого ожидания. Как мы видели в наших экспериментах, это позволяет быстро находить и фиксировать оптимальное действие, выдавая практически оптимальный накопленный результат.
Но является ли сэмплирование Томпсона лучшим решением задачи многорукого бандита? И что ещё важнее, стоит ли его использовать для зарядки Малыша Робота? Об этом мы расскажем в следующей статье, в которой сравним друг с другом все алгоритмы!